

개요
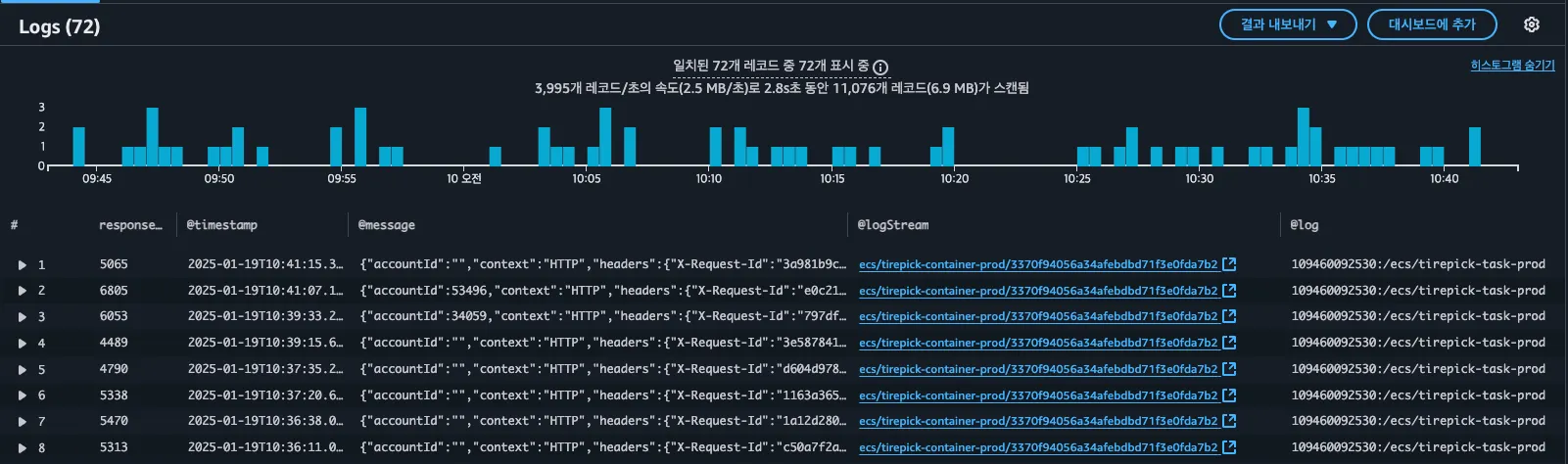
19일 10분 4분 경 모든 API responseTime이 5초 이상 걸리는 현상이 발생
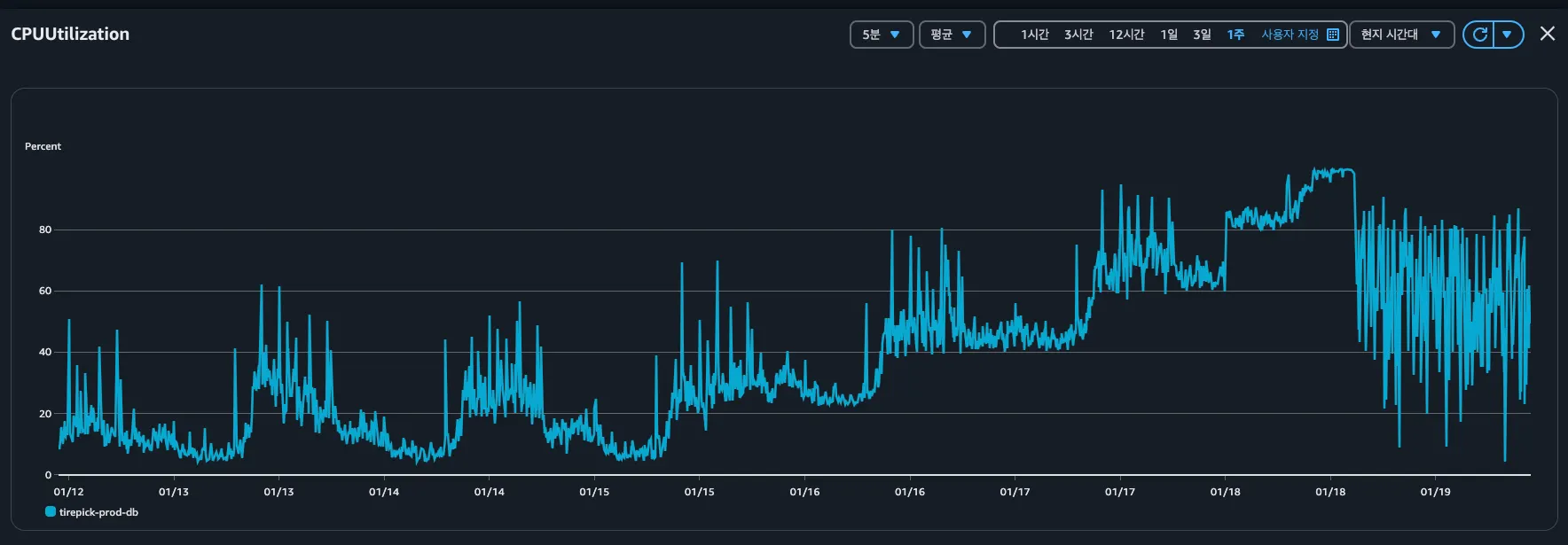
1월 19일 2시 경부터 CPU 사용량이 99% 내외를 머무르는 것으로 확인됨, CPU 사용량은 서서히 올라간 것으로 보임
원인분석
확인결과 thirdPartyLogging 내에 IF_BLACKCIRCLE_WEBHOOK FAIL 로그가 분당 100건 이상 과도하게 발생 중,
이 로그는 타이어픽 주문과 블랙서클 주문을 동기화하기 위해 10분마다 black-circle-web-hook/order API 호출할 때 발생함
허나 실패 건에 대해서는 10분 배치가 아닌 1분 배치로 발생했다는 점으로 발생량이 과도하게 발생시킨 점으로 보임
결국 타이어픽 서버로 들어오는 과도한 요청량으로 인해 오버헤드가 발생한 것으로 보임
초동대응으로 과도하게 발생하는 트랜잭션을 중단하기 위해 로그 수집을 중단 처리(866f10b8fd5d9c72ecfb91ea144cb9bb454f9a55) 하였으나
CPU 사용량은 정상범위로 돌아오지 않음, black-circle-web-hook/order API는 몇백건 씩 호출됨을 상정하고 개발되어 있지 않았으며
해당 API를 호출하는 엔드포인트에서는 분당 최대 235 건을 요청하고 있어 유사 DDOS 공격과 같이 트랜잭션이 과도하게 생성되는 현상 인한 것으로 확인됨
그렇다면 왜 발생했는가를 정리해보면
사건의 발단은 삭제된 주문 건이 배송이 진행되면서 발생함, 현재 주문연동 이후 주문이 정상 진행되지 않는 버그가 발생하고 있어 이에 대한 사이드 이펙트로 판단됨
평일의 경우 주문이 삭제되어도 고객센터를 통해 빠르게 인지하고 처리가 가능했으나, 주말에 진행된 건은 바로 확인이 되지 않았던 것이 문제의 발단으로 생각됨
장애 시나리오는 아래와 같이 진행됐을 것으로 보임
1.
모종의 이유로 요청받은 주문목록의 250건 중 삭제된 주문이 발견된다면 해당 주문 건을 만나는 순간 해당 요청을 끊어버림
2.
엔드포인트에서는 요청이 끊겼기 때문에 실패로 간주하여 250건을 전부 다시 요청
3.
목록 내의 250건 중 삭제된 주문을 만날때까지 동일한 트랜잭션을 발생시킴
4.
3번 항목과 함께 실패 건에 대해 1분마다 발생하는 로직으로 인해 RDS 과부하 진행
5.
실패된 주문 건이 쌓이면서 점점 더 많은 요청량을 보내게 됨
해결방안
현재 문제는 이미 처리된 경우에는 더 이상 호출이 되지 않아야 하나, 서버 지연현상으로 인해 5분 이상 반응이 없는 경우 타임아웃을 발생시켜 엔드포인트 입장에서는 해당 주문 동기화가 실패한 것으로 판단하여 1분마다 다시 요청을 하며, 타임아웃으로인해 정상처리되어야 하는 주문까지 처리되지않음
문제해결을 위해서는 지수백오프 방식을 도입하여 호출량을 줄이거나 이후 판매량이 증가하여 요청 건이 많아지는 경우에도 문제가 재발생할 여지가 있으므로 요청을 메시지-큐 처리 방식으로 변경 필요성이 있음
참조
SELECT * FROM pg_stat_statements
SELECT * FROM pg_available_extensions
WHERE installed_version is not null;
CREATE EXTENSION pg_stat_statements;
SQL
복사